1) Is this your first completely online subject?
|
Yes
|
2) What do you enjoy about the use of blogs during the subject? (Please provide a few sentences or bullet points.)
|
|
3) Do you feel group work via blogs is a productive way to work through the course concepts (e.g., Web 2.0, Information Architecture, Content Management, etc.)?
Please indicate on a scale of 1 to 10 (where 1 = Strongly disagree to 10 = Strongly agree)
|
1 2 3 4 5 6 7 8 9 10
|
4) What do you enjoy about the use of Facebook during the subject? (Please provide a few sentences or bullet points.)
|
|
5) Do you feel that the use of social networking enhanced your sense of being part of the class community given that there was no real-time interaction within the subject (i.e., lectures, tutorials)?
Please indicate on a scale of 1 to 10 (where 1 = Strongly disagree to 10 = Strongly agree)
|
1 2 3 4 5 6 7 8 9 10
|
6) What would you recommend to enhance the experience of a student in an online environment? (Please provide a few sentences or bullet points.)
|
|
Thursday, 25 October 2012
Survey - item 4
Google PageRank - item 4
PageRank is the algorithm used by Google's search engine. It is based on the theory that the importance of a research paper can be judged and rated by the number of citations the paper has from other research papers.
The inventors of the algorithm Sergey Brin and Larry Page, transferred the research paper importance theory to the web, making so each web page can be judged by the number of hyperlinks which are pointing to it from other web pages. (Horrell M., 2001)
What is this equation?
The inventors of the algorithm Sergey Brin and Larry Page, transferred the research paper importance theory to the web, making so each web page can be judged by the number of hyperlinks which are pointing to it from other web pages. (Horrell M., 2001)
 |
| Example of the theory behind PageRank. |
PR(A) = (1 - d) + d(PR(t1)/C(t1) + ... + PR(tn)/C(tn))
Legend:
- 'PR(A)' is the web page's PageRank
- 't1' & 'tn' are pages which link to page A
- 'C' number of outbound links the page has
- 'd' the damping factor (usually set at 0.85)
How does it work?
A simpler version to understand is:
a page's PageRank = 0.15 + 0.85 * (linking page's PageRank/number of outbound links on page)
In plain terms, a page's PageRank is calculated by dividing a page's number of inbound links with its number of outbound links (inbound/outbound). Then the value is multiplied by the damping factor. Finally the product of "1 minus the damping factor" is then added to the result. The final product is then achieved.
References
Horrell M.(2001), The Google PageRank Algorithm. Retrieved from http://www.markhorrell.com/seo/pagerank.html
References
Horrell M.(2001), The Google PageRank Algorithm. Retrieved from http://www.markhorrell.com/seo/pagerank.html
Monday, 15 October 2012
My Chosen Website - Item 3
This assessment item I have been asked to make a website using blueprints, wireframes, and metadata to show its shape, function, and strategy.
The kind of website I wanted to make was an information wiki made by university students who can edit all subject areas and create new pages. But first what is my target audience? I'm looking at an audience with these characteristics and backgrounds.
- Either female or male
- Ages 18-25
- Able to read
- Highly educated Students
- Within a Tafe or University community
- Has a social life for looking for information to their area of study
- Able to access the internet
 |
| Hierarchy Navigation for website. |
Here is the blueprint of the website's pages and functions.
It is a hierarchy navigational system. The website has 5 main functions which are also pages; home page, the advanced searching, adding new content, contact information, and post page.
The home page is an introduction to the site with a description of how to use the site.
The Select by Area (Hierarchy) is an advanced search page that gives the user a couple of ways to narrow down their search preferences using hierarchy. It then posts results the user can view.
The Add New Content allows logged in users to enter new content to the site. It goes through a process of asking the user where the content is contented under, as well as letting them enter the content. The user can then view the content with a preview on the website. If they want to edit, it takes them back to the Add New Content. Otherwise, it publishes the content and sends the user to the post page.
The Contact Us is a web page that gives information of the developers and owners, as well as their content information to send an email if they have a question or report of a bug of the website.
The Search is not a page, but a search box that can be used on any webpage of the website, that uses the query entered and uses algorithms to narrow the searches down and displays them in a list.
Here are the wireframes for the website. Descriptions for the wireframes are found in the images themselves.
 |
| Home page |
 |
| Contact Us page |
 |
| Advanced Search page |
Here is the metadata matrix which will be used for components of the website:
 |
| Metadata Matrix |
Tuesday, 25 September 2012
Chapter Summary of a Boring Book - Item 3
 I retract my previous blog post of the book "Information Architecture for the World Wide Web". The first three chapters of the book were brilliant. Chapters 5, 6, and 7 were mildly amusing. Now chapters 8, 9, and 12 have given me a poor view upon the book. Now the book just talks about common sense, no new information has ended up into my head from further reading.
I retract my previous blog post of the book "Information Architecture for the World Wide Web". The first three chapters of the book were brilliant. Chapters 5, 6, and 7 were mildly amusing. Now chapters 8, 9, and 12 have given me a poor view upon the book. Now the book just talks about common sense, no new information has ended up into my head from further reading.It does not get more amusing the further you go in, as a book should. Yet sadly, I still have to summaries this book and continue to press on to read it.
Chapter 8: Search Systems
Why is does a website need search? Any site's main goal is to keep a user on the site as long as possible and give them the right information a user is looking for.It is extremely hard to find information on a website if proper search systems are not put into place. Imagine trying to build a house from scratch, and you are trying to find where to drill the holes in the lumber, but have no blueprints.
There are many variables to consider into making a good search engine:
- Determining Search Zones - Search zones are subset of a website that have been indexed separately from the rest of the site's content. These zones eliminate content that are irrelevant to a user's needs. (E.g. When a user searches a search zone, they have identified that they are interested in that particular information). Most websites contain two types of pages:
- Navigation - contain main pages, search pages, and pages that help you browse a site.
- Destination - contain the actual information the user wants.
- Search zones can index information a number of ways:
- Indexing for specific audiences
- Indexing by topic
- Indexing recent content
Search Algorithms are under the skin of search engines, used to help find information. There are 40 different algorithms, but the book only describes a few:
- Pattern-Matching Algorithms
- Recall - Best used for finding quick, precise documents related to search.
- Precision - Best used for finding all documents related to search.
- Cited By - What other papers cite this one?
- Active Bibliography (related documents) - This paper cites others in its bibliography implying a similar type of shared relevance.
- Similar Documents Based on Text - Documents are converted into queries automatically and are used to find similar documents.
- Related Documents from Co-citation - Co-citation assumes that if documents appear together in the bibliographies of other papers, they probably have something in common.
Query builders also affect the result of a search. They are tools to advance a query's performance. Common one's are:
- Spell-checkers
- Phonetic tools - Used when searching for a name.
- Stemming tools - Used to find documents of the search with variant terms. (e.g. Lodge, lodger, lodging)
- Natural language processing tools - Used for syntactic nature of a query. Such as terms as "How to" or "Who is".
- Controlled vocabularies and thesauri - Used to expand the semantic nature of a query by automatically including synonyms within the query.
Listing these results can be ordered in many ways, by:
- Alphabet
- Chronology
- Ranking by Revelance
- Ranking by Popularity
- Ranking by Users'/Experts' ratings
- Ranking by Pay-For-Placement (PFP)
Designing the search interface poses many questions to be answered:
- Level of searching expertise and motivation
- Type of information need
- Type of information being searched
- Amount of information being searched
When designing the search box, we must consider searching options for the user, since it is being made for them. Some of these include: allowing the query to work without AND, OR, NOT, etc., typing in a term that describes the search, the query will search the entire site, and many more examples.
Some searches give an "advanced search" option, which not only give the user the insight of the functionality of the search engine, but gives them many perimeters to work with.
For helping a user hone in on their search, there are many techniques:
- Repeating the search in the results page
- Explaining where the results have come from
- Explain what the user has done
- Integrating searching with browsing
Chapter 9: Thesauri, Controlled Vocabularies, and Metadata
A single link on a page can simultaneously be part of the site’s structure, organization,
labelling, navigation, and searching systems. It’s useful to study these systems separately, yet it is crucial to understand how they interact.
Metadata - In data processing, meta-data is definitional data that provides information about or documentation of other data managed within an application or environment. For example, meta-data would document data about data elements or attributes (name, size, data type, etc.) and data about records or data structures (length, fields, columns, etc.) and data about data (where it is located, how it is associated, ownership, etc.). Meta-data may include descriptive information about the context, quality and condition,
or characteristics of the data. (e.g. <meta name="keywords" content="information architecture, content management, knowledge management, user experience">)
Controlled Vocabularies - come in many different forms. Vaguest form, a controlled vocabulary is any defined subset of natural language. Simplest form, a controlled vocabulary is a list of equivalent terms in the form of a synonym ring, or a list of preferred terms in the form of an authority file.
- Synonym ring - connects a set of words that are defined as equivalent for the purposes of retrieval.
- Authority file - is a list of preferred terms or acceptable values. Authority files have traditionally been used largely by libraries and government agencies to define the proper names for a set of entities within a limited domain. They are synonym rings in which one term has been defined as the preferred term or acceptable value.
 |
| A Synonym Ring |
 |
| An Authority File |
- Classification Schemes - is used to mean a hierarchical arrangement of preferred terms. (e.g. Dewey Decimal Classification (DDC))
- Thesaurus - Different from a common thesaurus, this one is integrated within a web site or intranet to improve navigation and retrieval, shares a common heritage with the familiar reference text but has a different form and function. Like the reference book, this thesaurus is a semantic network of concepts, connecting words to their synonyms, homonyms, antonyms, broader and narrower terms, and related terms.
 |
| Example of a Thesaurus |
- Classic - used at the point of indexing and at the point of searching. Indexers use the thesaurus to map variant terms to preferred terms when performing document-level indexing.
- Indexing - used when able to perform controlled vocabulary indexing, but not able to improve the work to the point of searching and mapping users’ variant terms to preferred terms. This is a has some weaknesses to it.
- Search - uses a controlled vocabulary at the point of searching but not at the point of indexing. This is used when dealing with third-party content or dynamic information that is changing every day or there is so much content that manual indexing costs would be astronomical.
What sets a thesaurus apart from the simpler controlled vocabularies is its large array of semantic relationships:
- Equivalence - employed to connect preferred terms and their variants.
- Hierarchical - divides up information space into categories and subcategories, relating broader and narrower concepts through the familiar parent-child relationship.
- Associative - the trickiest, and by necessity is usually developed after a good start on the other two relationship types. In thesaurus construction, associative relationships are often defined as strongly implied semantic connections that aren't captured within the equivalence or hierarchical relationships. (e.g. hammer & nail, or straw & milkshake).
Proper terminology is critical. The following are some aspects of terminology:
- Term Form - Defining the form of preferred terms is extremely difficult. Some questions that come up when selecting the for are "Use a noun or a verb?", "What is the correct spelling?", "Can an abbreviation be a preferred term?", etc.
- Term Selection - Selection of a preferred term involves not only the form, but the right term to work with in the first place. (e.g. Literary warrant (occurrence of terms in documents) is the guiding principle for selection of the preferred (term).)
- Term Definition - The right definition has to be recognised. (e.g. Cells [biology] or Cells [Prison])
- Term Specificity - Some terms might be recognised in many terms or just one, so it is critical to recognise it what they are to the user. (e.g. "Knowledge Management Software" could be broken down into many terms. It could be seen as "Software", "Knowledge of Software", or even as "Programs run by Computer".
- Polyhierarchy - When a term can be cross referenced among more than one hierarchy tree. (e.g. A "frog" and "toad" can both fit into being the top in the hierarchy tree for "characteristics of an amphibian".
- Preferred Term (PT)
- Variant Term (VT)
- Broader Term (BT)
- Narrower Term (NT)
- Related Term (RT)
- Use (U)
- Used For (UF)
- Scope Note (SN)
- Topic
- Product
- Document type
- Audience
- Geography
- Price
Chapter 12: Design and Documentation
Communicating Visually
As ideas are put to paper, it can be scary to realize there’s no going back. The project is now actively shaping what will become the user experience. Fears and discomforts will be diminished if time and resources have been implemented to do the research to help provide develop a strategy. Sometimes projects are pushed straight into design (which is quite common) which gives the project team the uneasy use of their intuition and "gut" instinct.
As ideas are put to paper, it can be scary to realize there’s no going back. The project is now actively shaping what will become the user experience. Fears and discomforts will be diminished if time and resources have been implemented to do the research to help provide develop a strategy. Sometimes projects are pushed straight into design (which is quite common) which gives the project team the uneasy use of their intuition and "gut" instinct.
There is no ideal solution for diagramming information architecture, let alone an agreed upon set of diagrams to work with. The field of information architecture is simple too young at this point in time to have a set criteria, but there are some strategies to help present it.
Communicating visually is usually the best way to show the content components and their connections with each other. These are called blueprints. They show relationships between pages and other content components to visually show organisation, navigation, and labelling systems.
These "blueprints" are usually created with a top-down approach, starting with the main page, and spreading through the website and its components. The best way to help clients and team members to understand a blueprint is to keep it simple (providing a legend for example), detail pages and content (with a unique identification number to link it to detailed documents relating to that content), and organising them (sometimes a blueprint is to large to be represented on one page, so splitting the blueprint up into multiple blueprints that relate is a good method).
 |
| A simple website blueprint. |
 |
| A visual design with the use of a wireframe implemented. |
Content mapping is where top-down approach meets bottom-up. The process breaking down or combining existing content into chunks that are useful for inclusion in your site. A content chunk is not necessarily a sentence, a paragraph, or a page. It is the most finely grained portion of content that merits or requires individual treatment. It could be information relating to the search engine and information organised which is categorised into a list for developer's and user's use.
Content models are “micro” information architectures made up of small chunks of interconnected content. Content models support the critical missing piece in so many sites: contextual navigation that works deep within the site. Why a missing piece? Because it’s too easy for an organization to accumulate blobs of content, but extremely difficult to link those blobs together in a useful way.
Controlled Vocabularies
There are two primary types of work products associated with the development of controlled vocabularies:
- Metadata matrixes that facilitate discussion about the prioritization of vocabularies
- An application that enables you to manage the vocabulary terms and relationships.
An information architect’s job is to help define which vocabularies should be developed, considering priorities, time, and budget constraints.
 |
| Example of a Metadata Matrix |
After all these design and documentation concepts have been developed, other stakeholders involved in the site (visual designers, developers, content authors, or managers) will be collaborating together more frequently. It is the most challenging step in design, since everybody wants their own ideas to play a role in the final product. Because of this, there are often competing vocabularies and breakdowns in communication.
The best course of action is for everyone goes in with an open mind, and collaborate together. This gives a shared vision that is more satisfying that a personal one.
Design sketches are an inventive approach to collect knowledge of multiple teams in a project as a first attempt at interface design towards "top-level" pages for a website.
The process is quite simple. Wireframes as a guide, the designer can sketch pages of the site on paper. As the design sketches each page, questions arise from other members that must be discussed. It is very cheap and fast approach compared to creating HTML pages with graphics.
Prototypes are used later after the base design has been agreed upon and all questions asked. They show how the site will look and function, they are concrete and aesthetically appealing. Another benefit of a prototype is that they can show unseen problems/properties related to information architecture.
Point-of-Product IA
As an information architect, it is their job to be actively involved to make sure the architecture is implemented according to plan and to address any problems that arise. Many decisions must be made during production. Some include:
- Are these content chunks small enough that we can group them together on one page, or should they remain on separate pages?
- Should we add local navigation to this section of the site?
- Can we shorten the label of this page?
Answers to these questions may impact a burden on the production team as well as the usability of the
website. An information architecture needs to balance requests of the client with the sanity of the production team, the budget and timeline, and their vision for the information architecture of the website. They shouldn’t need to make major decisions about the architecture during production because these should have already been made.
Sunday, 16 September 2012
Facebook's Information Architecture - Item 2
 |
| Facebook with Navigational and Link Components |
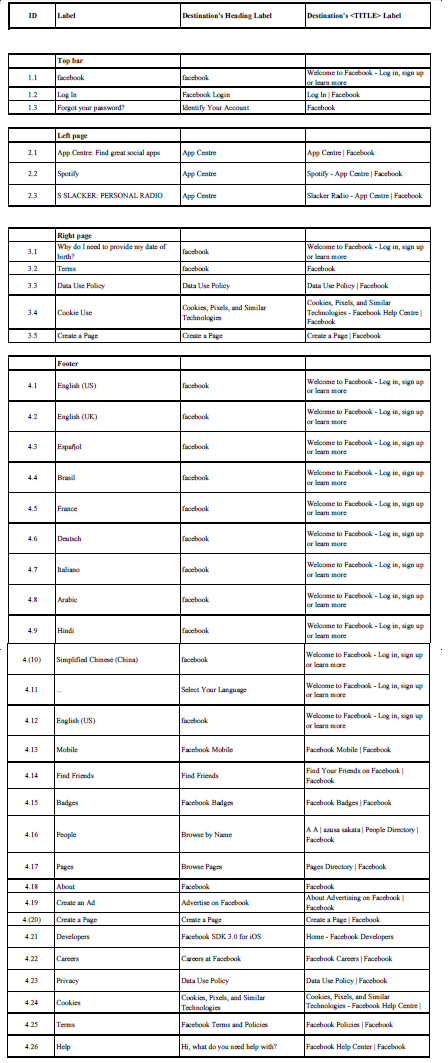 |
| Label Table for Facebook |
I was very annoyed with examining the labels of the Facebook home page. Most of the time with the footer, the labels were very miss leading, or made no sense.
Most of the footer labels would change their targeted audience after the user clicks it, or would lead to a page unrelated to what the label description is.
An example of this would be the label "Developers". It leads to a page with it's title being Facebook SDK 3.0 for iOS, yet the <title> tag says "Home - Facebook Developers". When I clicked this, I thought I'd find the details of the people who created Facebook. Instead I find a part of Facebook that is meant for developing apps for the Facebook or sites to link to Facebook.
The label could be a bit more descriptive like, "Developers Home Page" or "Developing App Centre", something that gives off where the link will take the user.
Another thing I did not like about the labels was there where doubles of links over the page. "English (US)" was used twice in the footer of the home page. Even now I still do not know why.
The a few of the labels linked to the exact same page as each other, yet each label described a different thing. For example, "Privacy" and "Data Use Policy" both link to the "Data Use Policy | Facebook" page. Why not just include them together? It makes less clutter on the website and makes it easier for a user to navigate with fewer options.
One annoying feature of the footer labels were all the language labels at the bottom. Now I know what the Facebook developers were trying to do because I'm use to the advanced understanding of the web. Although, other users who are not trained to understand this, would find it very confusing with all the different languages. They should be labelled in a descriptive way that says something like "For picking your language, click here", and have that put in a couple of different languages itself for quick understanding to a user.
One more thing I did not like with the footer labels, was one particular label itself. Even with my advanced knowledge, I could not figure out what the label "..." meant along with the language labels. I click on it and it shows a pop up with multiple languages to select. I mean what in the world! How does "..." mean "More languages to select"? Very confusing to a user, even with knowledge in website. Not only this, but I only spotted the label by accident when I was copying the home page to edit and put onto this blog.
Two competing sites popped into my head when I was asked to find sites that competed or resembled the same labelling information architecture as Facebook: Twitter and MySpace.

Twitter uses the same general information layout for it's home page like Facebook.
Header has the it's symbol that links to the twitter home page like Facebook has.
Left side of the site has a little bit of information about what the site is about while Facebook has navigation to apps relating to itself.
Right side of site has quick sign in features like Facebook as well.
Footer has similar labels to Facebook's footer labels.
Yet all of this, I can see Twitter has done a better job. The expansive labels for choosing your language was confusing and to crowded. Twitter has put the language in the top right part of the site with a label, "Language:" with a drop down arrow for choices of languages. Much easier to understand than Facebook. Also I could guess and understand where the footer's labels would lead me too. The "Developers" label still got me annoyed since it was still not descriptive enough, but all in all, I prefer Twitter's home page layout better than Facebook's. A lot easier to understand and handle.

MySpace has taken a different approach to Facebook and Twitter all together. It is trying to make an image for itself. It's header still uses the same approach as the other two social networking sites, but with a difference. Even though the Symbol sends the user to the home page, it adds other navigational labels for searching quickly through common topics being looked at (e.g. Such as Music, Video, Games, Browse People). It every has sign in squeezed up the top with a search bar.
The middle of the site is comprised of a number of images relating to chronological ordered items under the subjects mentioned before in the header (Music, Video, Games, Browse People). Just above the footer is a bunch of lists separated by topic.
The footer is crowded with more topic lists. Each label I clicked showed me exactly what I thought what page I would be taken too. Easy to understand the layout if given the time to look at all the information.
But is there a clear winner? I'd have to say a tie between Twitter and MySpace. While Twitter has the less crowded interface with easy navigation, MySpace has easy to understand, descriptive labels, making navigation a bit easier when doing known-item searching. If these could be implemented into one, this would be, in my opinion, the best social networking website ever implemented.
(Side Note: If anyone can tell me how to link a PDF file to a blog, it would be very helpful so people could see the Facebook label list clearly. Thank you.)
Saturday, 15 September 2012
Information Organisation - Item 2
- Describe what role an Information Architect plays in the development of a web site. An Information Architect plays an enormous role in the development of a website. They are the key to presenting information clearly to the user, depending on the what information they trying to find. In other words, an Information Architect are the arrows in a large labyrinth to help get to the middle faster, without getting lost.
- Arrange the following list in alphabetical order, then answer the questions below: (completed)
- #!%&: Creating Comic Books
- $35 a Day Through Europe
- 1-2-3 of Magic, The
- 1001 Arabian Nights
- Albany, New York
- El Paso, Texas
- H20: The Beauty of Water
- Hague, Netherlands, The
- Lord of the Rings, The
- St. Louis, Missouri
- Saint Nicholas, Belgium
- New York, New York
- Newark, New York
- Plzen, Czech
- XVIIme siécle
- .38 Special
a) Did you put The Hague under T or H? Under H, "The" is emphasizing a topic.
b) Did you put El Paso under E or P? Under E because it is a name of a landmark.
c) Which came first in your list, Newark or New York? New York comes first, because spaces are sorted first before anything else.
d) Does St. Louis come before or after Saint Nicholas? St. Louis. Abbreviations are treated as fully spelt.
e) How did you handle numbers, punctuation, and special characters? As stated by the document "Guidelines for Alphabetical Arrangement of Letters and Sorting of Numerals and Other Symbols" (found here: http://www.niso.org/publications/tr/tr03.pdf), Spaces are highest priority, symbols other than numerals, letters, and punctuation marks come second, numbers third (0-9), letters fourth (A-Z), punctuation marks comes last.
f) Assuming the italicised terms are book titles, what might be a more useful way to organise the list? Organise the list into two different lists, with one of them with the heading "Book Titles" and the other list heading "Other".
g) If the cities represent you've visited and the book titles are ones you've read, how could chronology be used to order the list in a more meaningful way? By sorting the information from titles read and cities been visited, being highlighted and sent to the bottom with oldest viewed item being the last.
h) Look at how some of the other students have organised this information and comment on their blogs.
Tuesday, 4 September 2012
Chapter Summaries of a Great Book - Item 1
This book is quiet a good read, "Information Architecture of the World Wide Web, 3rd edition". I usually hate reading text books but this one was well written and keeps making me want to read more.It talks about what Information Architecture really is, and the processes and skills behind it. I will summaries a few of these from chapters 5, 6, & 7.
Chapter 5: Organisation Systems
This chapter talks about how we always organise our information for everything and ways we organise. For example, we live in towns which are in states which are in return inside countries. This is an example of "Bottom-Up" Hierarchy organisation.
There are a lot of challenges involved in organising information, such as:
- Ambiguity: words are capable of being understood in more ways than one.
- Heterogeneity: referring to a collection of objects or parts that are unrelated.
- Differences in Perspectives: everyone views things or sets things differently.
- Internal Politics: Choice of organisation and labelling can have a big impact on how users perceive a company, group, or person.
There are a number of organisation schemes. They come under two categories, Exact and Ambiguous.
Exact:
- Alphabetical
- Chronological
- Geographical
Ambiguous:
- Topic
- Task
- Audience
- Metaphor
- Hybrids
Organisation structures include:
- Hierarchy: Top-Down Approach
- Database Model: Bottom-Up Approach
Hypertext systems involve two components, the items or chunks of information to be linked, and the links between those chunks. Hypertext systems are page transitions for example. Clicking a link in a Wikipedia article will take the user to information linked to that link.
Free tagging is another way of organising. It involves the users to tag one or more key words to objects. These key words act as pivots so mass information can be found easily to a single key word being searched for. Users can move swiftly through objects, authors, tags, and indexers this way.
For example, Del.icio.us is a web application that allows users to tag saved bookmarks to describe the link. This allows easy searching for search engines.
Chapter 6: Labeling Systems
Labelling is important because it is a form of representation. Such as using speech to represent concepts and thoughts, we use labels to represent larger chunks of information in websites.
Types of labels:
The rest of the text is quite dull on this subject, nothing much left to describe (The text continues to go into indepth analysis of these types of labels and how to design them, often repeating itself).
Chapter 7: Navigation Systems
As you may assume, this chapter is all about Navigation. It describes how navigation is like the story, "Hansel and Gretel". Users will get lost extremely quickly on the World Wide Web unless they leave a trail of breadcrumbs to show their path.
It is important investigate the environment which the system will be implemented in. A lot of users use different web browsers such as Mozilla Firefox and Microsoft Internet Explorer to move around websites. Different web browsers use many different built-in features. A different web browser can force a user to enforce different views on a website's navigation.
Before a navigation is plotted, we have to locate our position. Many users jump in to a random page of a website from search engines. This can be really confusing navigating a site since the home page is usually skipped. A good course of action to check if a user can recognise the "here you are" in a website is to test them. First user jumps directly into a random page of the website, skipping the home page. Can the user figure which they are in relation to the website? Can they tell where the page will lead to next? Are the links descriptive so the user understands what they are about?
The design of navigation systems is deep in the "grey area", meaning it can very in many ways. This is because the design is comprised of information technology, interaction design, information design, visual design, and engineering. Now you can see why it is very hard to form a well-designed navigation system.
Hierarchy is powerfully familiar way to sort a website's information. It is used often. A web's hypertextual capabilities (i.e. search engine) remove the hierarchy to give freedom to travel anywhere in the website. But make sure the website leaves "breadcrumbs", or some sort of "you are here" label or you can get lost.
Types of Navigation Systems:
Types of labels:
- Contextual - Hyperlinks to chunks of information on other pages or to another location on the same page.
- Headings - Labels that simple describe the content that follows.
- Navigation System Choices - Labels representing options in navigation.
- Index terms - Keywords, tags, and subject heading all represent content for searching or browsing.
Iconic labels are quite a difficult bunch. Just as the saying goes, "A picture means a thousand words", so does an iconic label. A lot of study and analysis has to go into creating an iconic label. Users can get quite confused with navigation or subject matters if they are not clear enough or without text to describe them.
The rest of the text is quite dull on this subject, nothing much left to describe (The text continues to go into indepth analysis of these types of labels and how to design them, often repeating itself).
Chapter 7: Navigation Systems
As you may assume, this chapter is all about Navigation. It describes how navigation is like the story, "Hansel and Gretel". Users will get lost extremely quickly on the World Wide Web unless they leave a trail of breadcrumbs to show their path.
It is important investigate the environment which the system will be implemented in. A lot of users use different web browsers such as Mozilla Firefox and Microsoft Internet Explorer to move around websites. Different web browsers use many different built-in features. A different web browser can force a user to enforce different views on a website's navigation.
Before a navigation is plotted, we have to locate our position. Many users jump in to a random page of a website from search engines. This can be really confusing navigating a site since the home page is usually skipped. A good course of action to check if a user can recognise the "here you are" in a website is to test them. First user jumps directly into a random page of the website, skipping the home page. Can the user figure which they are in relation to the website? Can they tell where the page will lead to next? Are the links descriptive so the user understands what they are about?
The design of navigation systems is deep in the "grey area", meaning it can very in many ways. This is because the design is comprised of information technology, interaction design, information design, visual design, and engineering. Now you can see why it is very hard to form a well-designed navigation system.
Hierarchy is powerfully familiar way to sort a website's information. It is used often. A web's hypertextual capabilities (i.e. search engine) remove the hierarchy to give freedom to travel anywhere in the website. But make sure the website leaves "breadcrumbs", or some sort of "you are here" label or you can get lost.
Types of Navigation Systems:
- Global - a navigation system that is to be present on every page through a website.
- Local - a navigation system that is present on pages related to a certain area of a website. e.g. Sub-menus.
- Contextual - a navigation system that is used to link to specific page, document, or object in a website. e.g. Clicking an image on Google Images to take the user to the image.
Supplemental navigation systems are external to the basic hierarchy of a website. They provide extra ways to search for finding content or completing tasks. These are:
- Sitemaps - Just like a table of contents in a book or magazine, just implemented on the website.
- Site Indexes - Just like indexes found in many printed materials, a website's site index presents keywords or phrases alphabetically. This is great if a user is knows what they are looking for.
- Guides - Can take on many forms (guided tours, tutorials, and micro-portals). They focus around a specific audience, topic, or task, and often serve as tools for introducing content (e.g. When you get a new electronic product for the first time and it brings up a tutorial on the device itself).
- Search - Search engines that look in the websites parameters for information.
- Wizards and configurations - Considered a special class for a guide, they help users configure products and navigate through complex decisions for their product.
Some advanced navigation approaches include personalization and customization. Personalization involves serving tailored pages to the user based on their behaviour, needs, or preferences of one individual. Customization involves allowing the user full control over presentation, navigation, and content options.
Subscribe to:
Posts (Atom)